Canoe Intelligence Product Update – June 2020

A Note from the CEO
Since our last product update, we’ve continued to make great strides in improving system performance and developing the Canoe Intelligence solution to meet the needs of all types of clients working with or allocating to alternatives.
In times of increased remote work and uncertainty like these, the need for scalable and accessible technology becomes even more important. We’re proud to be a part of the solution.
Below, we highlight some of the larger enhancements made to the Canoe Intelligence platform across the end-to-end operational workflow that incorporates document ingestion and categorization to data extraction, validation, and delivery.

As always, we welcome any and all feedback in continuing to solve the manual data problem facing our industry. We’re in this together.
Keep Paddling,
Seth Brotman, CEO
This article highlights the progress made within each of the workflow pillars above.

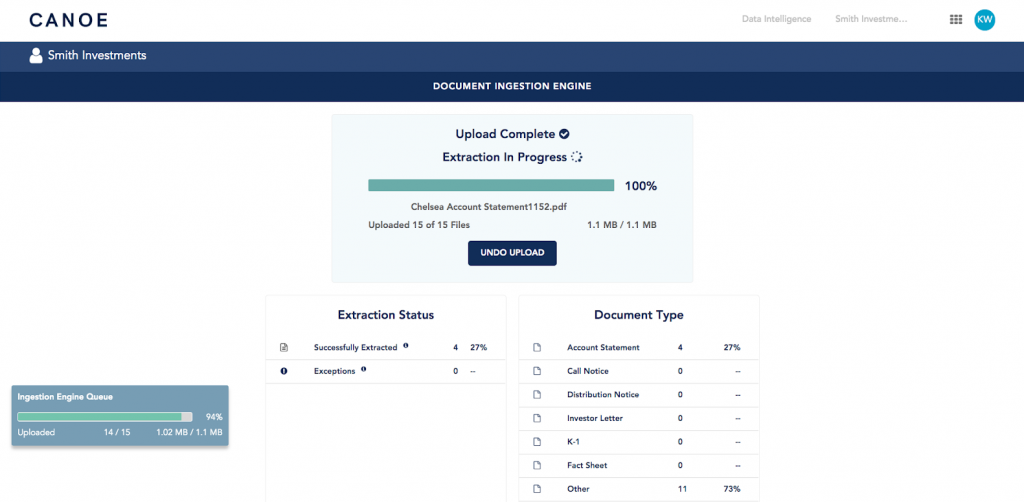
Decoupling Document Uploads from Data Extraction
When new documents are introduced into Canoe, the system initiates two processes: Upload and Extract. In our most recent release, we’ve separated the upload process from the extraction process for documents uploaded via the Ingestion Engine, allowing for improved performance.

Improved Flexibility for All Document Management Tasks
- Streamline the approval of your investment documents before sending the data to your downstream systems with a new Document Approval Workflow
- Create and update Accounts, Entities, Investments in bulk using the Ownership Configuration Engine
- Easily navigate between documents and track your mapping workflow with UX improvements in the Data Mapping Model
- Seamlessly view processed documents with a new user type, “Organization – View Processed”
- Delete documents in bulk via the API, saving time and increasing efficiency
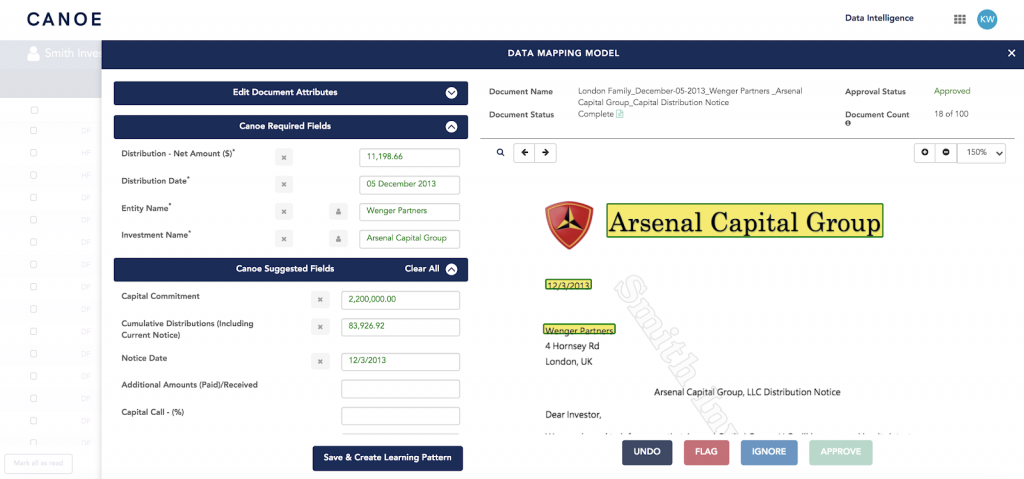
Document Approval Workflow: Approve, flag, or ignore documents as you review them within the Data Mapping Model

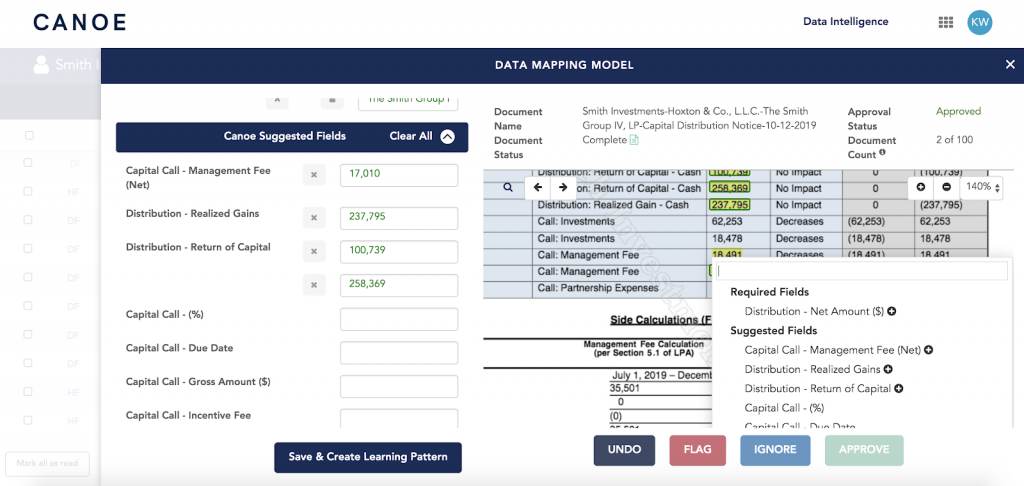
Advanced Support for Complex Document Types
- Extract data seamlessly from documents with multiple allocations
- Improved extraction of footnotes and tabular data structures
- Ability to better support complex document formats by extracting multiple data points for Canoe Required Fields and Canoe Suggested Fields

Ongoing Support for Multiple Downstream Systems
- Expanded Canoe’s field library with updates to the Investment Metrics extract, and the Black Diamond Transactions and Black Diamond Valuations extracts
- Restructured the API to accommodate multi-allocation formats